Bayesian Prophesies
summary
We created an interface, called Thesaurus, that allows data scientists to collaborate with Gamalon’s A.I. in real time to build custom models for their natural language data.
project
Gamalon wanted to productize its natural-language-processing technology for enterprise clients.
role
Product designer
Adventures in Surveyland
Consider a common question that companies ask their customers: “How likely are you to recommend this product to others?” In a standard survey, the answer is collected in two parts: first, a multiple-choice question with a few options; and second, a text box as an open-ended opportunity to elaborate further. In such cases, the mutliple-choice responses can be averaged and analysed with relative ease to get a rudimentary picture of customer satisfaction. But the real insights into how cusomters feel is hidden in the open-ended responses. When analysed at scale, these responses would reveal the specific reasons why customers feel the way they do. Consequently, organizations would stand to gain valuable insights about how to stay competitive and relevant.
A. How likely are you to recommend this product to others?
B. Please elaborate on your answer.
[Figure 1] A common two-part survey question that collects both structured and unstructured data from responders.
Natural Language is a Goldmine
Many organizations collect large amounts of natural-language data, such as chat messages, phone call transcripts, and survey responses, from their customers. These data sources hold a treasure trove of information about the motivations and needs of the community. However, most organizations are not equipped with the resources they need to process and interpret natural-language data at scale.
It is practically impossible for human beings to process large amounts of natural-language data. Many organizations receive thousands of responses each time they send out an open-ended survey. Even with a team of full-time human workers, it would take weeks to make sense of the data. This has fuelled the rise of natural language processing, or NLP, a type of artificial intelligence that employs machine learning and linguistic principles to interpret natural language data at scale.
“I am unhappy with your product because it's expensive.”
sad customer | clear reason
“I am unhappy with your product, but not because it's expensive.”
sad customer | unclear reason
“It's not that I'm unhappy with your product, but it's expensive.”
happy customer | unclear reason
[Figure 2] An example to illustrate how small changes in context and proximity of words can lead to radically different meanings.
Making A.I. More Transparent
Gamalon is a leader in the field of NLP. Our algorithms employ Bayesian deep learning techniques to build hierarchical language models capable of procesing gargantuan datasets in real time. In a recent project for a leading automobile manufacturer, Gamalon was able to process one million survey responses with 90% accuracy is less than a week.
Moreover, unlike many other artificial intelligence algorithms, Gamalon’s technology is not a black box. Instead, each thread of logic is available for inspection and alteration by humans. This provides for a rich environment within which to cultivate the growth of fairer, more robust language models that can be systemically cleansed of undesirable biases.
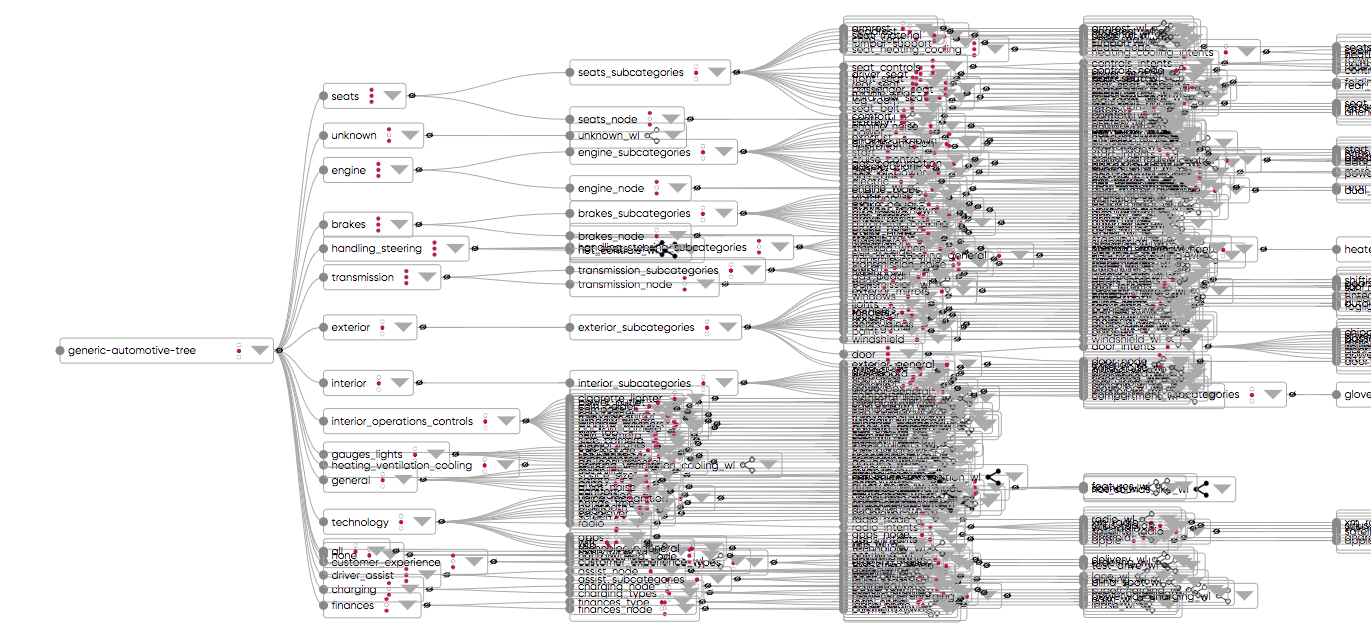
[Figure 3] A hierarchical natural language model developed using Gamalon's technology and rendered using d3. Lower-level nodes of the hierarchy have been compressed for display purposes.
Human-Machine Collaboration
Until recently, Gamalon followed a waterfall process for building its language models. Early on, a Gamalon data scientist kicked off the model-building process, after which the model went through several rounds of unsupervised learning. At the end of each round, the data scientist stepped back in to inspect progress and make necessary adjustments to ensure that classification results have improved since the previous round.
At the beginning of 2019, we decided to move away from this workflow by developing a graphical interface to allow humans to monitor model building in real time. This tool would be the first tool of its kind in the world - an interface for synchronous human-AI collaboration. We imagined that this tool would allow Gamalon’s technology to be be used by data scientists at client organizations to build their own bespoke language models on site, without having to share confidential customer information with outside vendors.
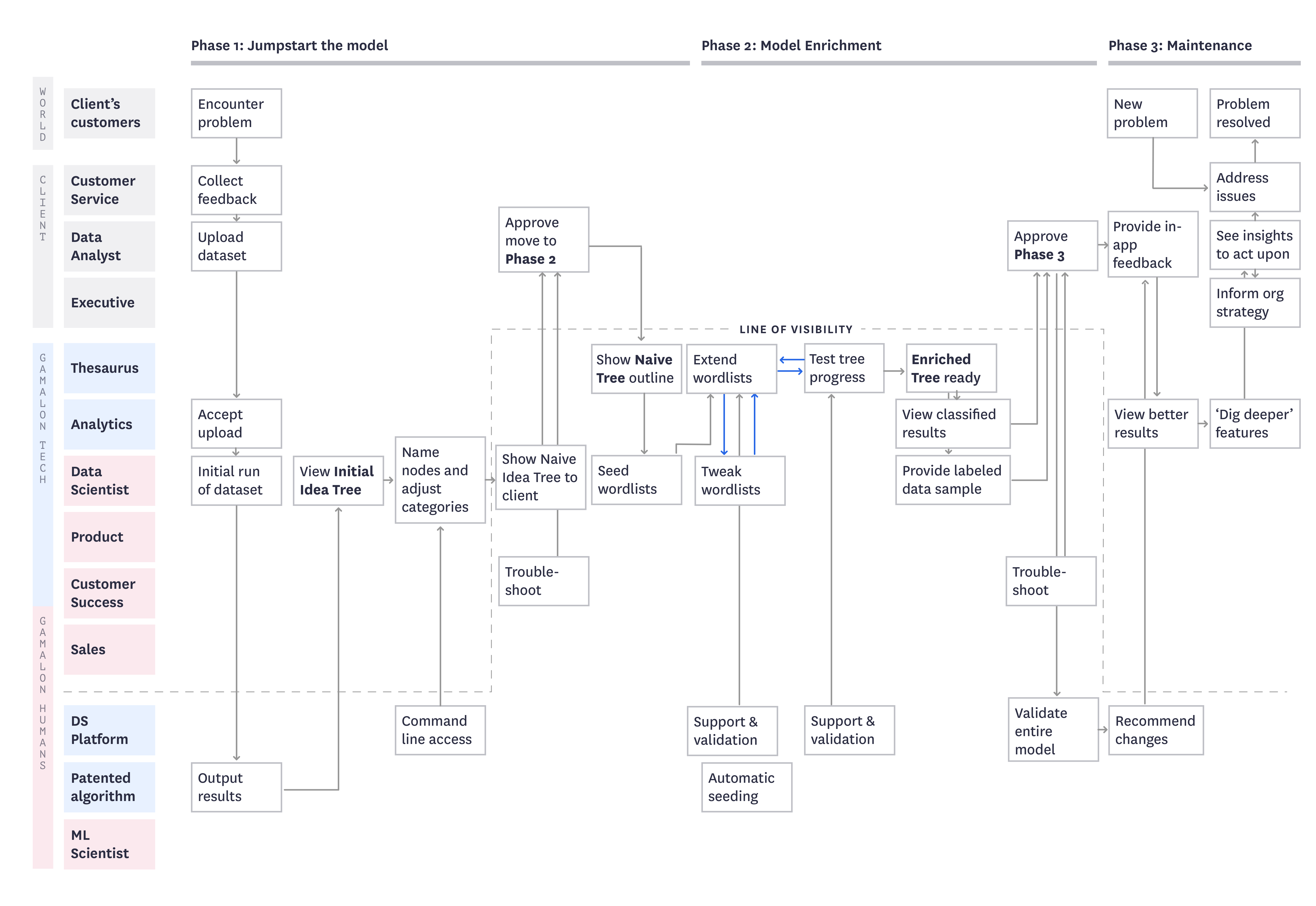
[Figure 4] A service blueprint mapping out Gamalon's plan for human-machine collaboration.
Creating a Probabilistic Interface
The unit of the Gamalon’s language models is the idea. An idea is a named collection of related linguistic objects, such as words and phrases. For example, the idea “partner” might include wife, husband, spouse, boyfriend, girlfriend, fiancé, lover, etc. The idea “make a payment” might include pay by cash, pay by card, Venmo, write a check, send a money order, wire transfer, etc. In Gamalon-speak, ideas are arranged into a hierarchy to form the language model. So, lower-level ideas, such as “money” could be included within higher-level ideas, such as “make a payment.”
To enable humans and A.I. to collaborate, we decided to create a graphical interface that reveals language models being assembled by Gamalon's technology in real time. Humans might collaborate with the A.I. in two ways. First, they might tweak the individual units of the model, i.e. the ideas, as the model was being assembled. Second, they might adjust the hierarchy of ideas in the model by trimming, cutting, copying, and pasting branches of the hierarchical model.
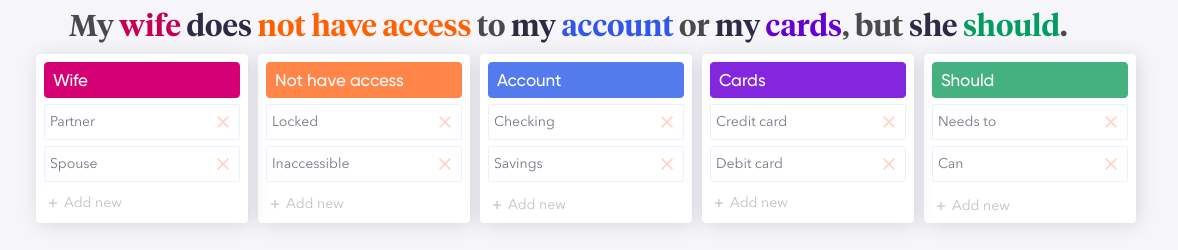
[Figure 5] A sentence annotated with its component word-level ideas. Each idea is accompanied by two representative synonyms.
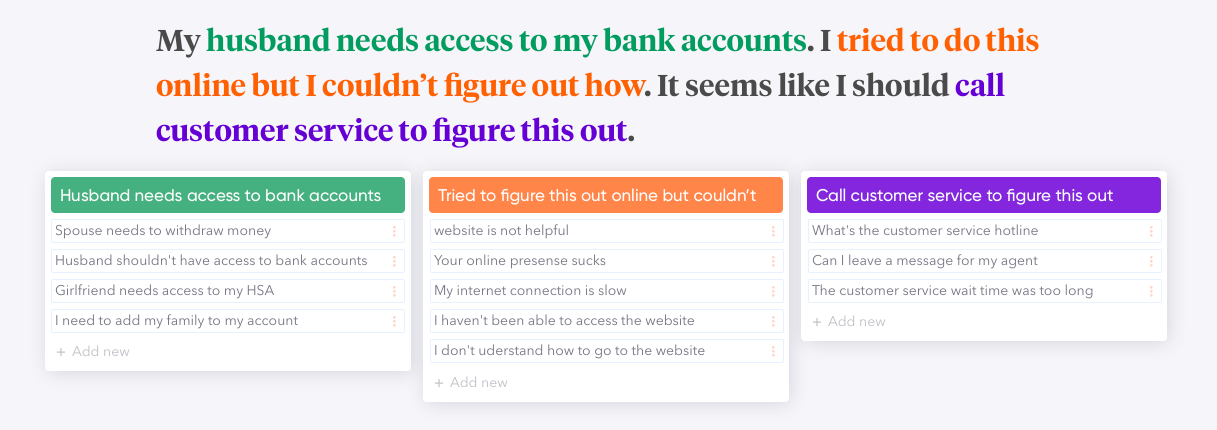
[Figure 6] Word-level ideads can be combined to form phrase-level ideas, as shown by this example.
Iteration I
Hypothesis
A single datapoint, i.e. a piece of natural-language data, is an efficient window into real-time model assembly.
Outcome
In isolation, a single piece of natural language does not provide enough context about the component synonyms of an idea. Consequently, the assembled model ends up being overfitted to specific data points rather than the dataset as a whole.
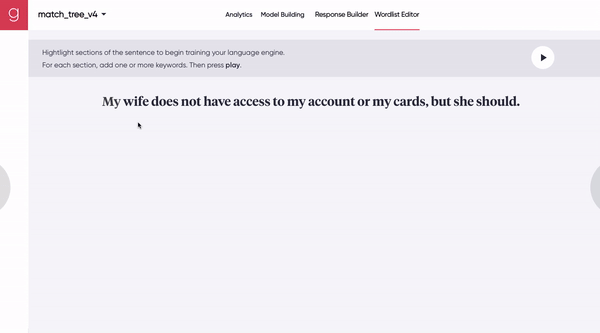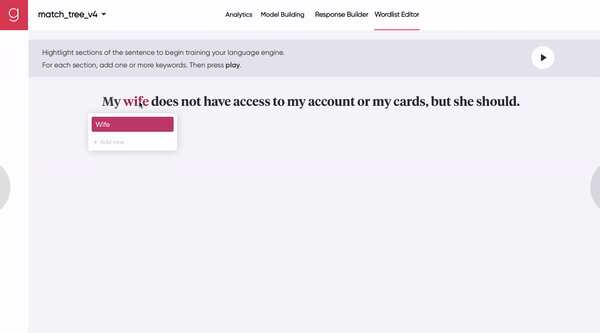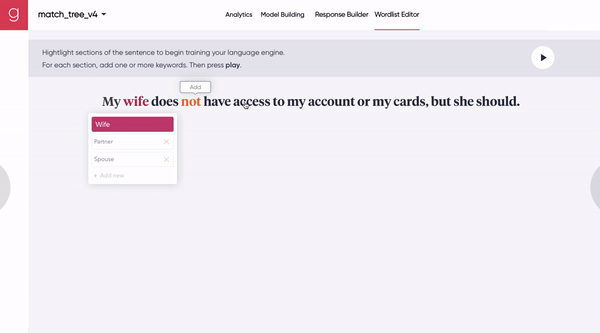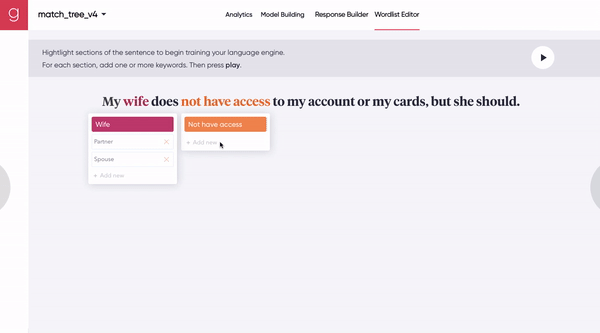
[Figure 7A] A human uses a synchronous human-machine collaboration tool to seed the model with a few representative synonyms.
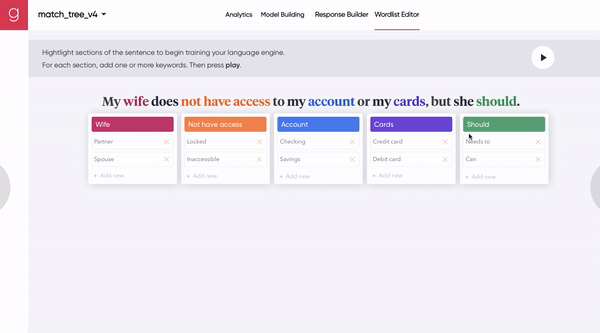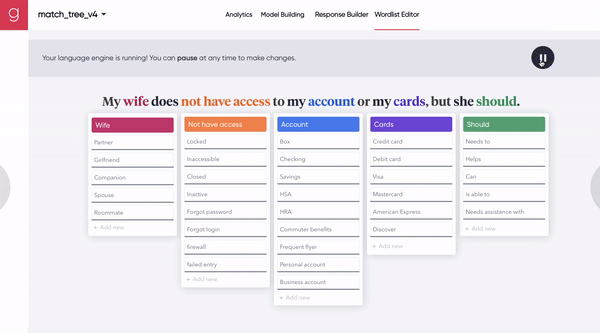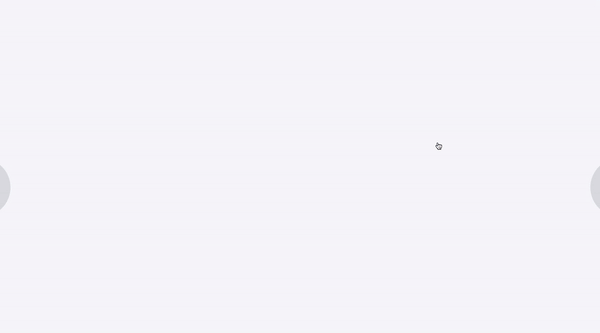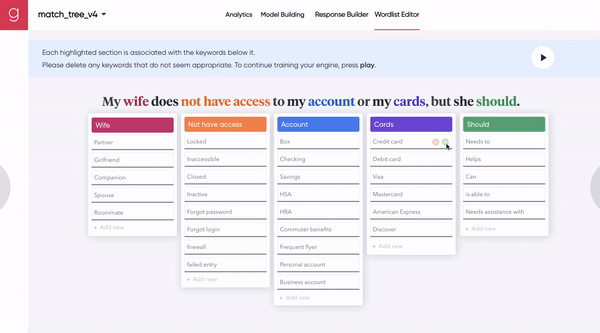
[Figure 7B] The A.I. builds out the model (by identifying more synonyms for each idea), and a human provides additional input.
Iteration II
Hypothesis
Model assembly is revealed via clustered groups of ideas that occur together, and representative datapoints serve as instances to provide the context needed for humans to collaborate with the A.I.
Outcome
Clustered groups of ideas restrict the data scientist to freely explore a model as it is being assembled. There is a need to provide a high-level view of the entire model.
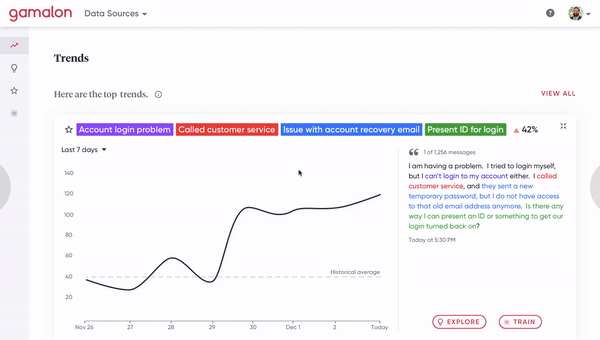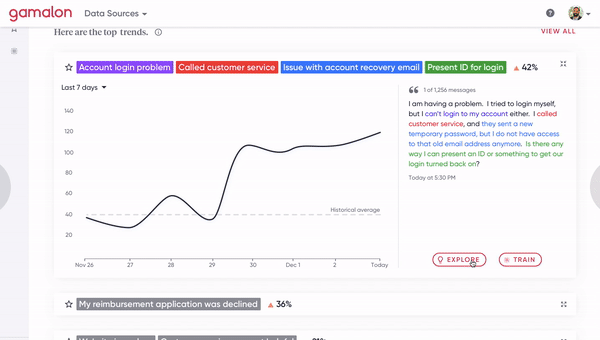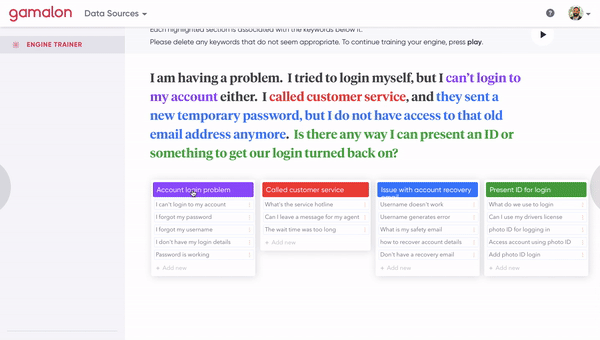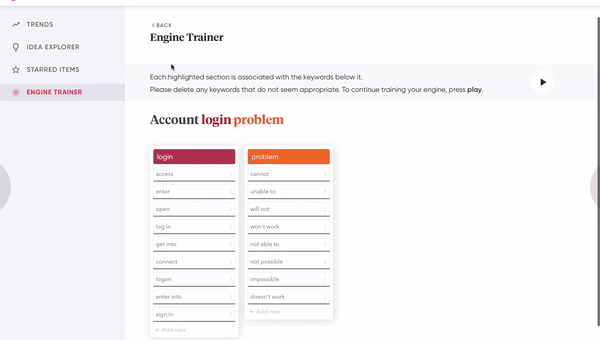
[Figure 8A] A human clicks on a phrase-level idea to inspect the constituent word-level ideas that compose it.
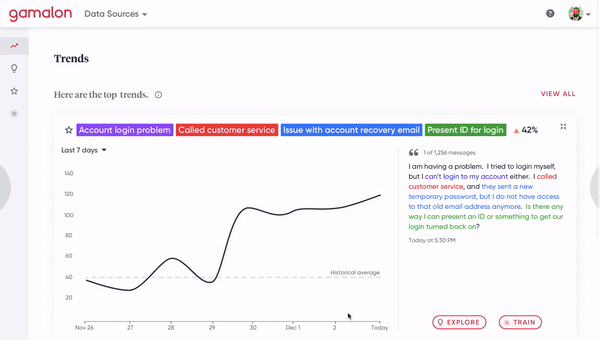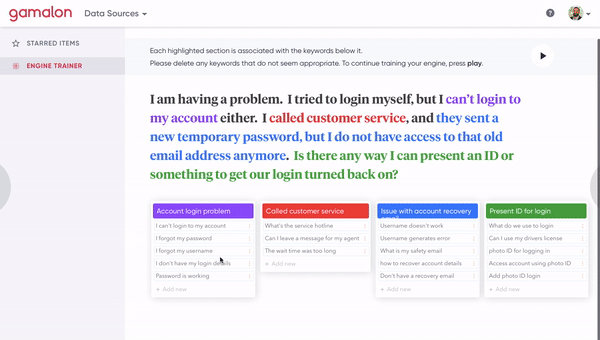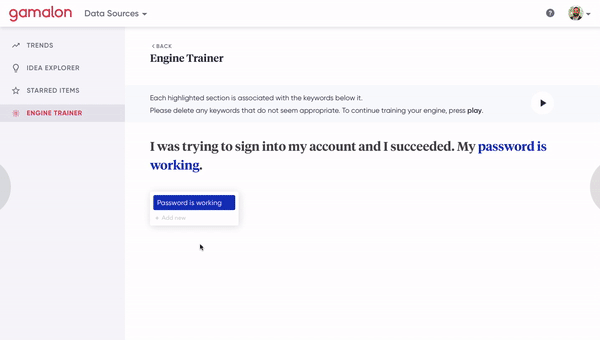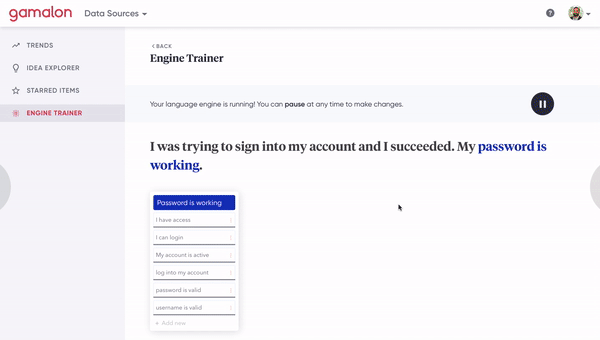
[Figure 8B] A human clicks on a synonym of a phrase-level idea to fork it off into a distinct phrase-level idea. This involves changing the architecture of the tree.
Iteration III
Hypothesis
For best results, a high-level view of the entire model should be accompanied by the ability to inspect and tweak individual ideas.
Outcome
Humans are unable to supervise more than a handful of ideas at a time, so the model needs to be trained in chunks, one at a time.
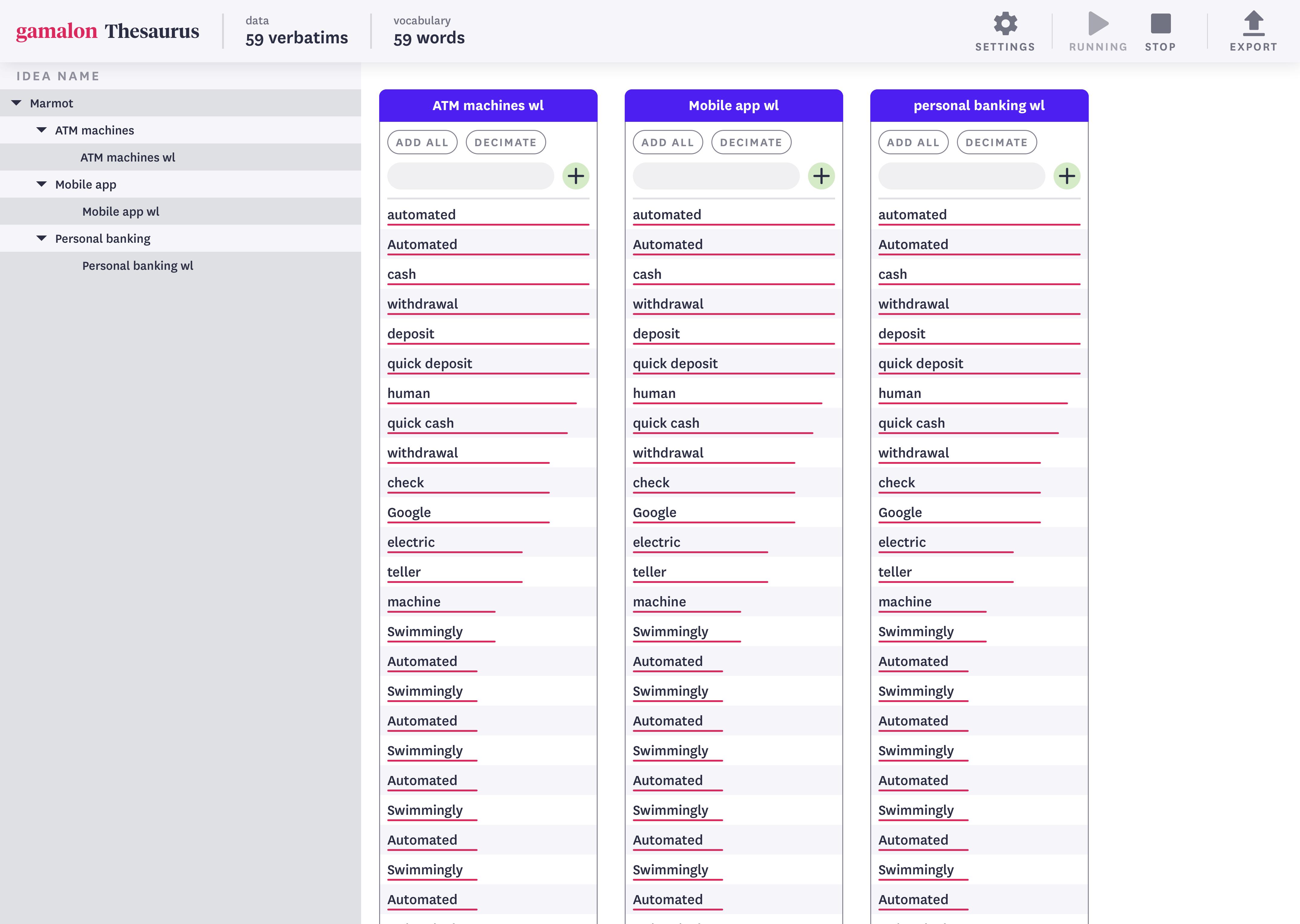
[Figure 9A] An interface stripped of natural-language datapoints, showing only the branches of a hierarchical model (left panel) and its constituent ideas (right panel).
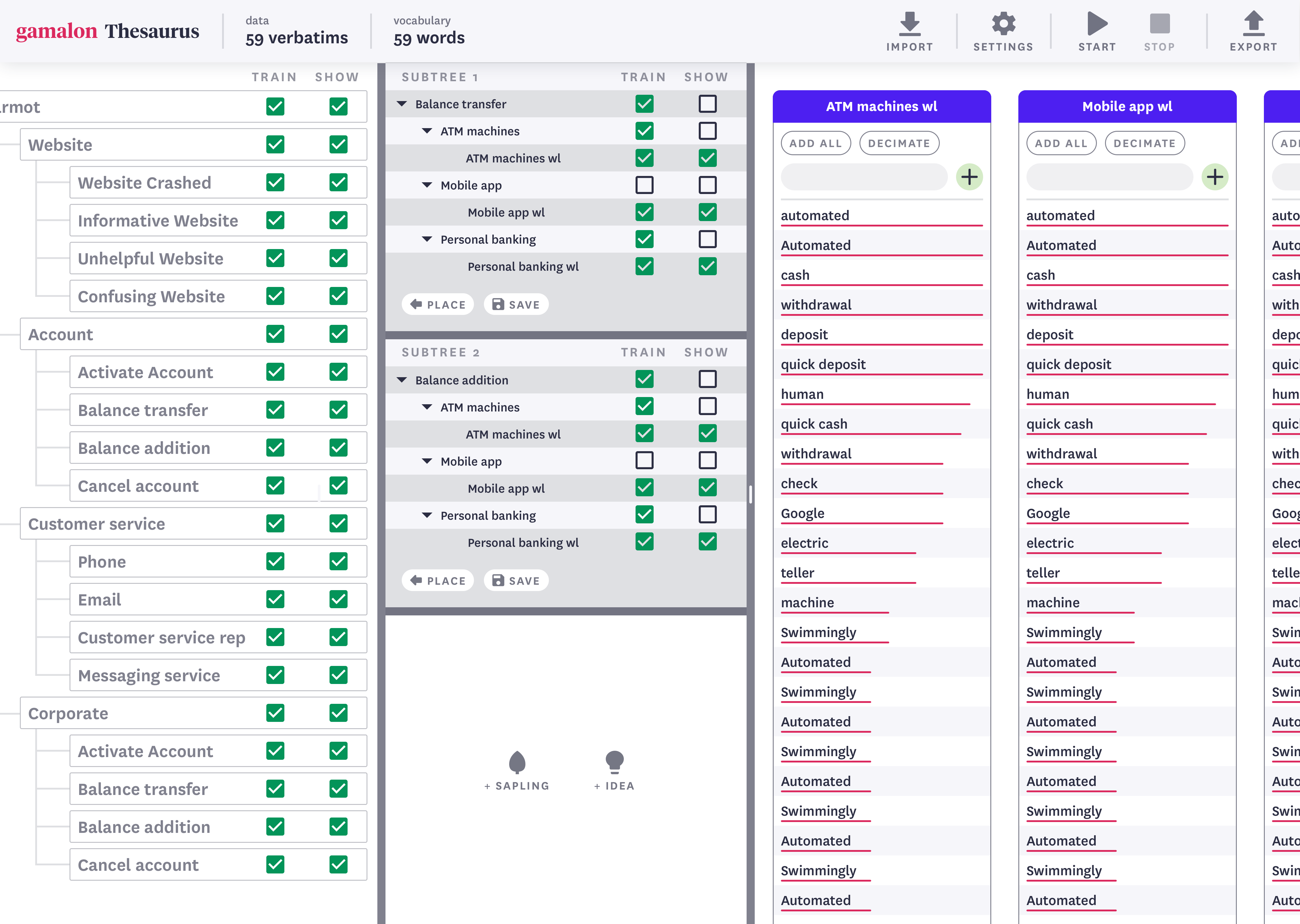
[Figure 9B] An interface showing the hierarchical model (left panel), two constituent branches of the model (center panel), and constituent ideas (right panel).
Final Design
After three rounds of iteration, it was clear to us that a high-level view of the model was important to reveal at all times during the human-machine collaboration process. Accordingly, we decided to build out an interface that draws closely from the third iteration, with two minor adjustments. First, we added idea-level controls to allow humans to control which parts of the model were being trained. Second, we wired up the interface with a Jupyter Notebook so that we could continue rapid iterations within the context of the existing data science workflows of our clients.
In March 2019, we rolled out the tool, newly christened Thesaurus, to a select group of beta testers. Here's a video showing Thesaurus at work, constructing a model to differentiate between brands, flavors, and quantities in a body of unstructured text data about edible consumer products.
[Figure 10] A speeded-up video showing a data scientist collaborating with Thesaurus to build a language model about edible consumer products. Skip ahead and pause at 3:19 to see the results of the model-building exercise.
Project Outcomes
[Faster Model Building] Thesaurus reduced the time required by data scientists to build models by 40%.
[Higher Transparency] Thesaurus allows data scientists to keep a closer watch on language models as they were being assembled. This improved our ability to detect and eliminate bias with greater efficiency.
[Tech-agnostic Workflows] Thesaurus allows our clients to build models using Gamalon's technology without having to understand exactly how our technology works on the backend. This affords the twin benefits of expanding access to Gamalon's algorithms while limiting the exposure of its intellectual property.
[Data Privacy] Thesaurus allows our clients to use Gamalon's technology on-site at their organizations, without having to access remote servers or the cloud. This allows our clients to process their data without having to share it with external vendors.


